https://github.com/sanyecao-seckill
1.3.3.1.1. 面临问题:
巨大的瞬时流量、热点数据问题、刷子流量
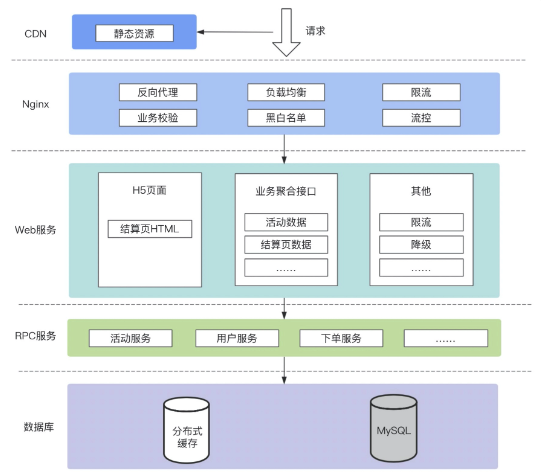
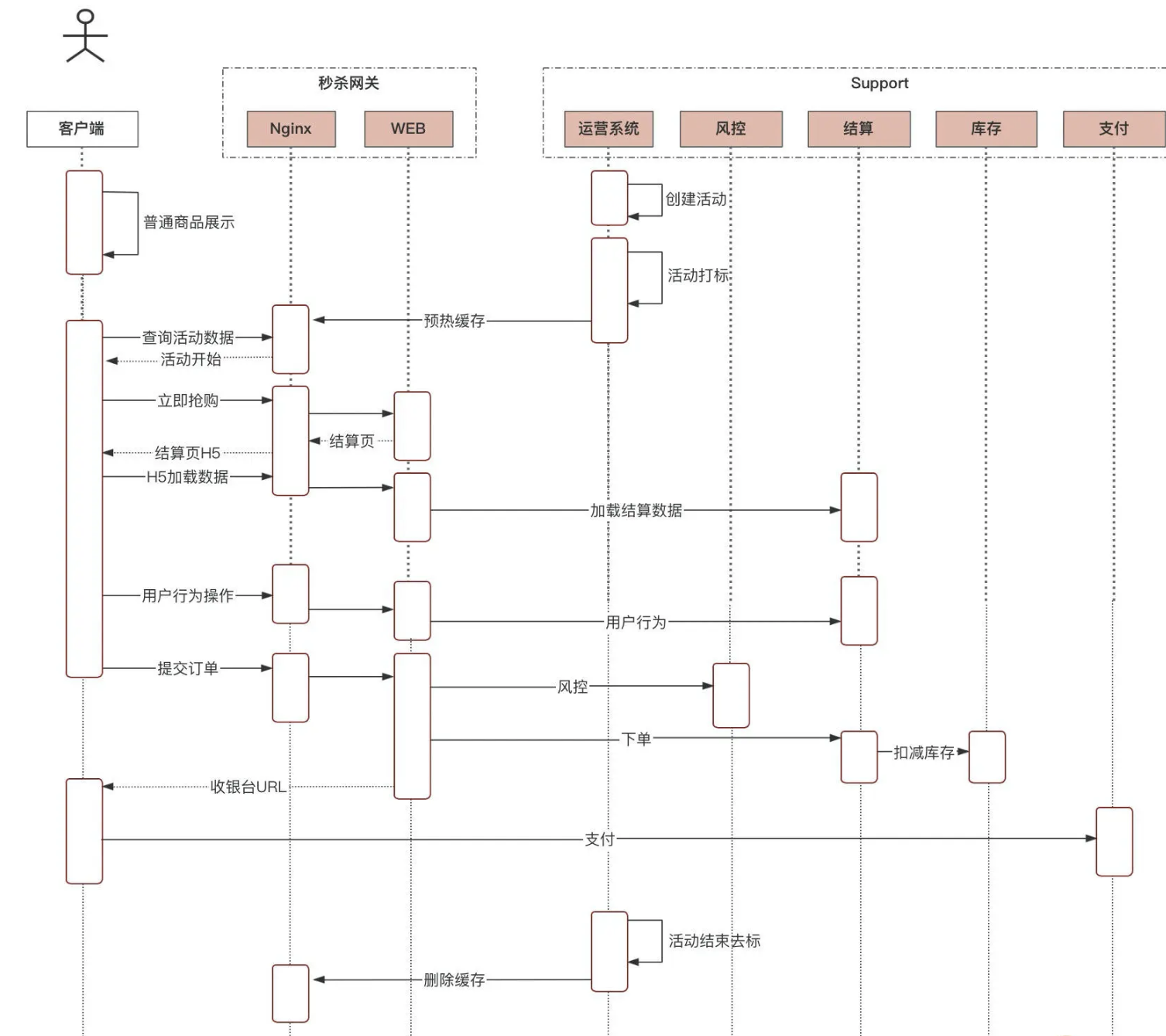
1.3.3.1.1.1. 链路路径
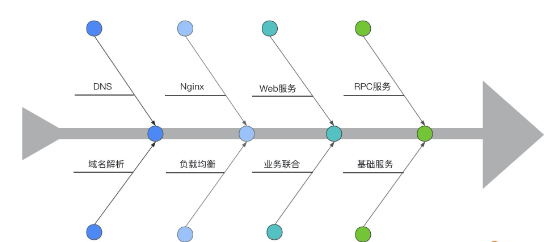
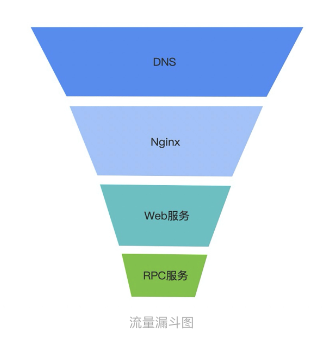
刷子请求,一部分是无效请求(传参等异常),剩下的才是正常请求,这个的比例可能是 6:1:3
1.3.3.1.1.2. NGINX
模块化、事件驱动、异步、非阻塞、多进程单线程
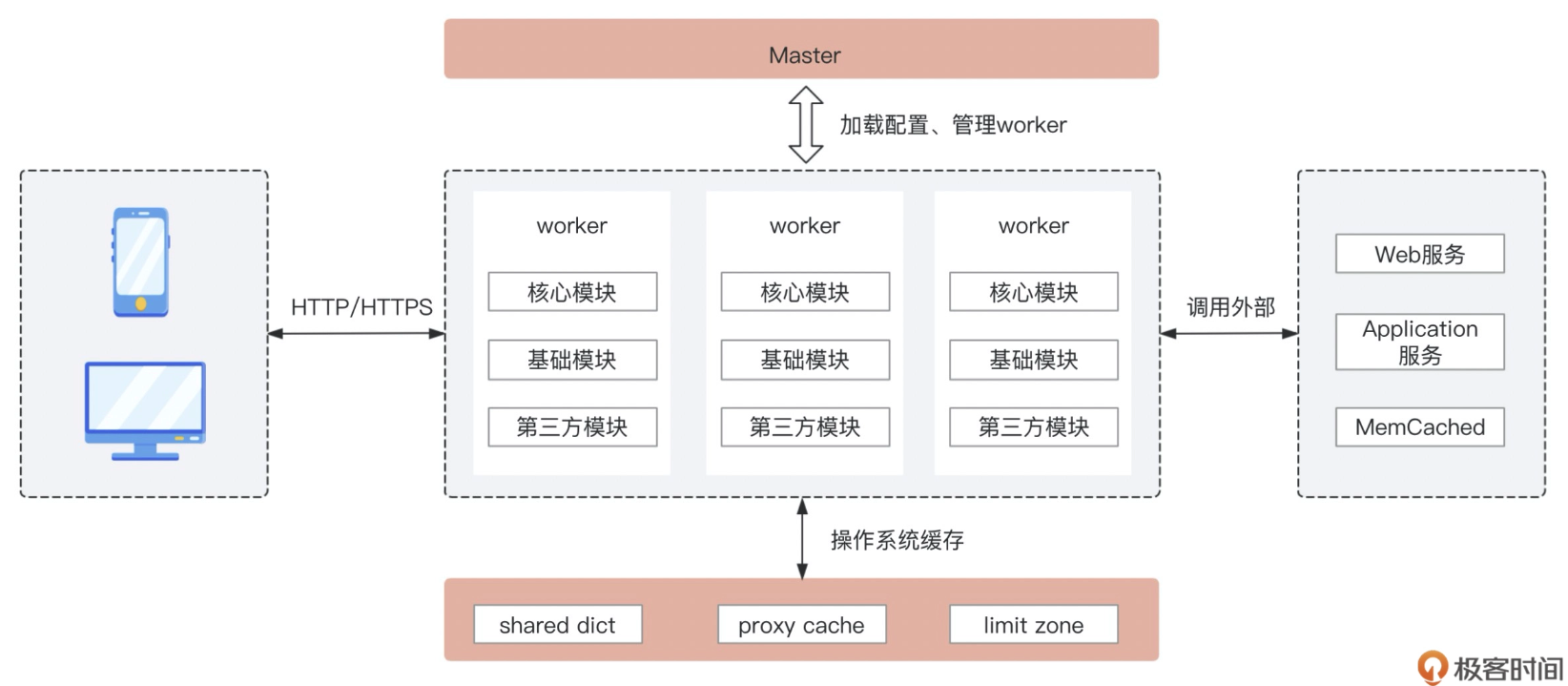
Lua 的线程模型是单线程多协程的模式,而 Nginx 刚好是单进程单线程,天生的完美搭档。
1.3.3.1.2. 秒杀隔离
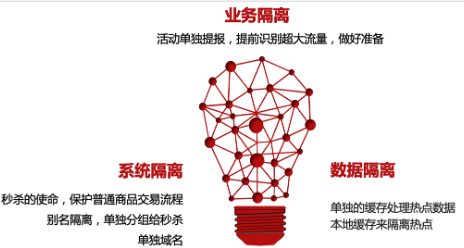
1.3.3.1.2.1. 业务隔离
商家或者业务可以根据自己的运营计划在提报系统里进行活动提报,提供参与秒杀的商品编号、活动起止时间、库存量、限购规则、风控规则以及参与活动群体的地域分布、预计人数、会员级别等基本信息
1.3.3.1.2.2. 系统隔离
比较常见的实践是对会被流量冲击比较大的核心系统进行物理隔离,而相对链路末端的一些系统,经过前面的削峰之后,流量比较可控了,这些系统就可以不做物理隔离
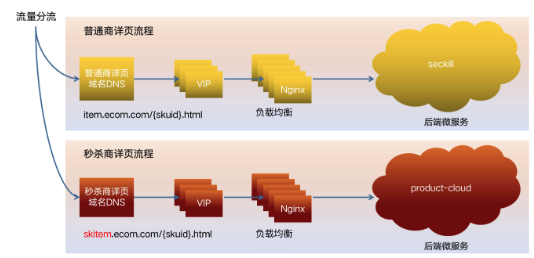
需要申请独立的秒杀详情页域名,独立的 Nginx 负载均衡器,以及独立的详情页后端服务,并采用 Dubbo 独立分组的方式单独提供秒杀服务。
负载均衡器都是软件方式,有 LVS、HAProxy、Nginx 等,一方面是出于成本考虑,毕竟大厂的网络规模非常大,单个 F5 的硬件成本能承受,但是大规模的硬件成本就很高了;另一方面开源的软件也更加灵活和可定制。
我们仍需要对域名进行隔离,我们可以向运维部门申请一个独立的域名,专门用来承接秒杀流量,流量从专有域名进来之后,分配到专有的负载均衡器,再路由到专门的微服务分组,这样就做到了应用服务层面从入口到微服务的流量隔离
1.3.3.1.2.3. 数据隔离
Redis 一主多从来扛读热点数据,热点数据
首先业务通过提报系统对秒杀 sku 进行提报,系统对秒杀 sku 进行打标,从活动页、列表页或者搜索页点击商品的时候,系统就能识别出秒杀标,路由到秒杀的商品详情页域名,进而进入到专有 Nginx。
商品打标:
打标就是一个标记,我们可以使用一个 long 型字段 skuTags 来保存,long 是 64 位,每一位代表一种类型的活动,0 代表否,1 代表是,通过对 skuTags 进行二进制操作即可完成商品的打标和去标。假设秒杀的标识我们定义在 skuTags 的第 11 位,那么要给一个 sku 打上秒杀标,我们就可以对这个标实际进行“或”操作:skuTags=skuTags|1024,这样 skuTags 字段的第 11 位就变成了 1,对其它 bit 位没影响。去标过程相反,同样进行位操作,skuTags=skuTags&~1024,把第 11 位置为 0。
1.3.3.1.3. 流量管控
流量控制、削峰、限流、缓存热点处理、扩容、熔断
预约
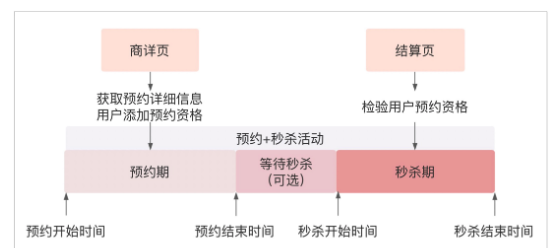
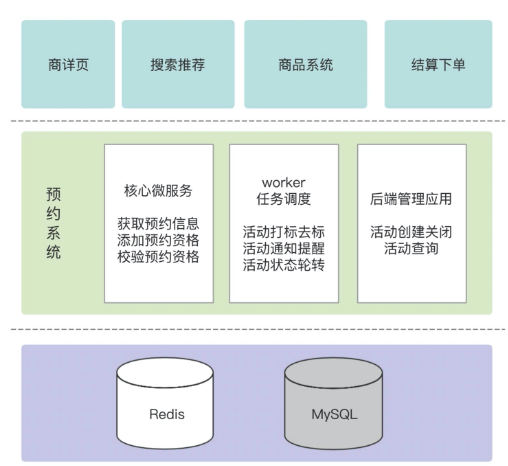
CREATE TABLE `t_reserve_info` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '预约活动id',
`sku_id` bigint(20) unsigned DEFAULT NULL COMMENT '商品编号',
`reserve_start_time` datetime DEFAULT NULL COMMENT '预约开始时间',
`reserve_end_time` datetime DEFAULT NULL COMMENT '预约结束时间',
`seckill_start_time` datetime DEFAULT NULL COMMENT '秒杀开始时间',
`seckill_end_time` datetime DEFAULT NULL COMMENT '秒杀结束时间',
`creator` varchar(255) DEFAULT NULL COMMENT '活动创建人',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`yn` tinyint(255) unsigned DEFAULT NULL COMMENT '是否删除',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `t_reserve_user` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '关系id',
`reserve_info_id` bigint(20) unsigned DEFAULT NULL COMMENT '预约活动id',
`sku_id` bigint(20) unsigned DEFAULT NULL COMMENT '商品编号',
`user_name` varchar(255) DEFAULT NULL COMMENT '用户名称',
`reserve_time` datetime DEFAULT NULL COMMENT '预约时间',
`yn` tinyint(255) unsigned DEFAULT NULL COMMENT '是否删除',
PRIMARY KEY (`id`),
KEY `reserve_id_ref` (`reserve_info_id`),
CONSTRAINT `reserve_id_ref` FOREIGN KEY (`reserve_info_id`) REFERENCES `t_reserve_info` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
redis
流量削峰
削峰手段:验证码、问答题、消息队列、分层过滤和限流
验证码和问答题:
一是快速拦截掉部分刷子流量,防止机器作弊,起到防刷的作用;
二是平滑秒杀的毛刺请求,延缓并发,对流量进行削峰。
推荐使用Google 提供的 Kaptcha 包生成图片验证码
/**
* 生成图片验证码
*/
@RequestMapping(value="/seckill/captchas.jpg", method=RequestMethod.POST})
@ResponseBody
public SeckillResponse<String> genCaptchas(String skuId, HttpServletRequest request, HttpServletResponse response) {
//从cookie中取出user
String user = getUserFromCookie(request);
//根据skuId和user生成图片
BufferedImage img=createCaptchas(user, skuId);
try {
OutputStream out=response.getOutputStream();
ImageIO.write(img, "JPEG", out);
out.flush();
out.close();
return null;
} catch (IOException e) {
e.printStackTrace();
return SeckillResponse.error(ErrorMsg.SECKILL_FAIL);
}
}
/**
* 生成验证码图片方法
*/
public BufferedImage createCaptchas(String user, String skuId) {
int width=90;
int height=40;
BufferedImage img=new BufferedImage(width,height,BufferedImage.TYPE_INT_RGB);
Graphics graph=img.getGraphics();
graph.setColor(new Color(0xDCDCDC));
graph.fillRect(0, 0, width, height);
Random random=new Random();
//生成验证码
String formula=createFormula(random);
graph.setColor(new Color(0,100,0));
graph.setFont(new Font("Candara",Font.BOLD,24));
//将验证码写在图片上
graph.drawString(formula, 8, 24);
graph.dispose();
//计算验证码的值
int vCode=calc(formula);
//将计算结果保存到redis上面去,过期时间1分钟
cacheMgr.set("CAPTCHA_"+user+"_"+skuId, vCode, 60000);
return img;
}
private String createFormula(Random random) {
private static char[]ops=new char[] {'+','-','*'};
//生成10以内的随机数
int num1=random.nextInt(10);
int num2=random.nextInt(10);
int num3=random.nextInt(10);
char oper1=ops[random.nextInt(3)];
char oper2=ops[random.nextInt(3)];
String exp=""+num1+oper1+num2+oper2+num3;
return exp;
}
private static int calc(String formula) {
try {
ScriptEngineManager manager=new ScriptEngineManager();
ScriptEngine engine=manager.getEngineByName("JavaScript");
return (Integer) engine.eval(formula);
}catch(Exception e){
e.printStackTrace();
return 0;
}
}
异步消息队列
我们把一步调用的直接紧耦合方式,通过消息队列改造成两步异步调用,让超过服务 B 范围的流量,暂存在消息队列里,由 B 根据自己的服务能力来决定处理快慢,这就是通过消息队列进行调用解耦的常见手段。
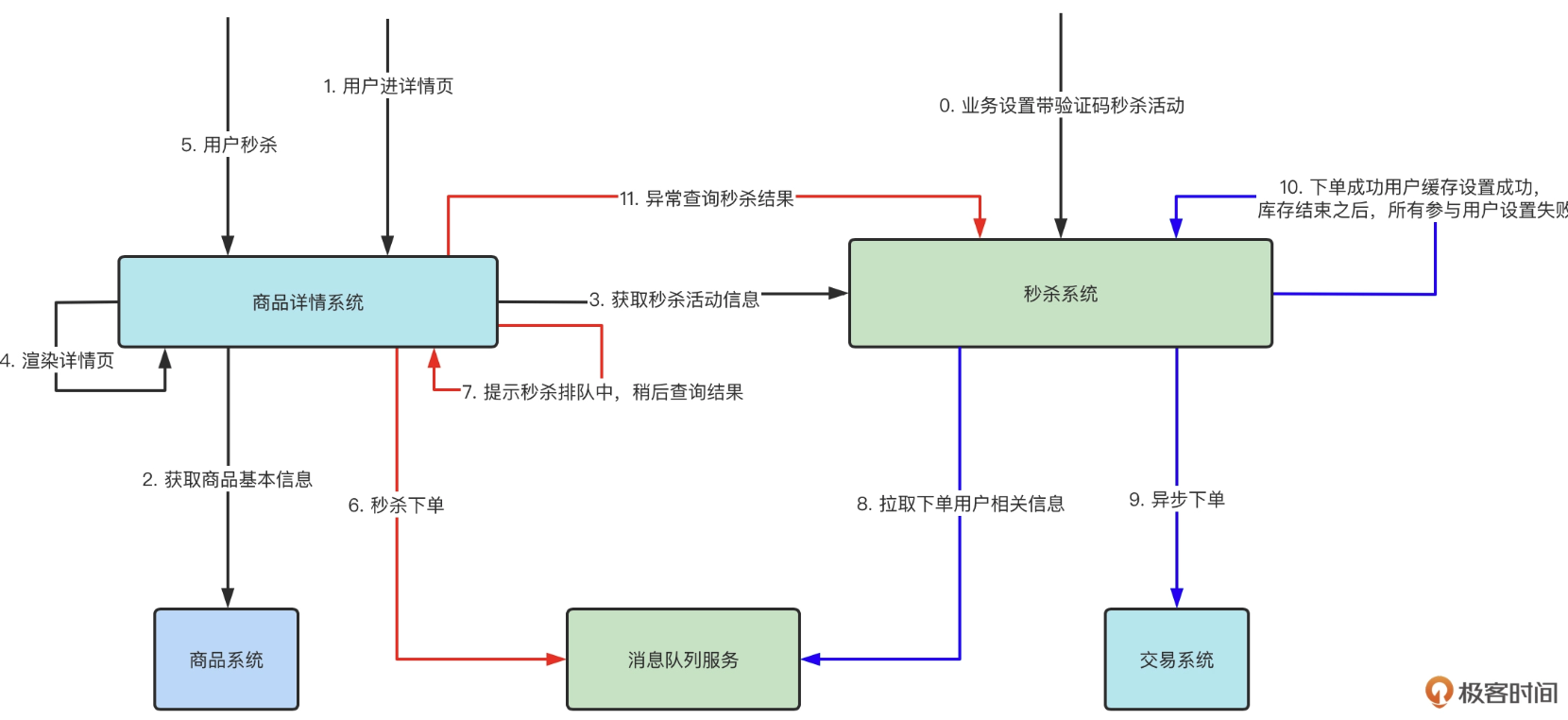
当前面的请求已经把库存消耗光之后,在缓存里设置占位符,让后续的请求快速失败,从而最快地进行响应
限流
Nginx 限流,主要是依赖 Nginx 自带的限流功能,针对请求的来源 IP 或者自定义的一个关键参数来做限流,比如用户 ID。其配置限流规则的语法为:
# 关键字限流
limit_req_zone <变量名> zone=<限流规则名称>:<内存大小> rate=<速率阈值>r/s;
## 举例配置
http {
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
server {
location /search/ {
limit_req zone=one burst=2 nodelay;
}
}
}
## 可以根据实际的情况调整 rate 和 burst 的值,在秒杀的场景下,一般我们会把 rate 和 burst 设置的很低,可以## 都为 1,即要求 1 个 IP1 秒内只能访问 1 次
# 基于用户id限流
limit_req_zone $user_id zone=limit_by_user:10m rate=1r/s;
线程池限流
并发数限流,对于并发数限流来说,实际上服务提供的 QPS 能力是和后端处理的响应时长有关系的,在并发数恒定的情况下,TP99 越低,QPS 就越高。
API限流
Google 提供的 RateLimiter 开源包,自己手写一个基于令牌桶的限流注解和实现,在业务 API 代码里使用。当然了,大厂中都会有通用的限流机制,你直接用就行了。
/**
* 自定义注解 限流
*/
@Target({ElementType.PARAMETER, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface MyRateLimit {
String description() default "";
}
/**
* 限流 AOP
*/
@Component
@Scope
@Aspect
public class LimitAspect {
//引用RateLimiter,内部是基于令牌桶实现的
private static RateLimiter rateLimiter = RateLimiter.create(100.0);
//定义限流注解的pointcut
@Pointcut("@annotation(com.seckill.aop.MyRateLimit)")
public void MyRateLimitAspect() {
}
@Around("MyRateLimitAspect()")
public Object around(ProceedingJoinPoint joinPoint) {
Boolean flag = rateLimiter.tryAcquire();
Object obj = null;
try {
if(flag){
obj = joinPoint.proceed();
}
} catch (Throwable e) {
e.printStackTrace();
}
return obj;
}
}
降级
1、写服务降级,牺牲数据一致性获取更高的性能
写数据库降级成同步写缓存、异步写数据库,利用 Redis 强大的 OPS 来扛流量,一般单个 Redis 分片可达 8~10 万的 OPS,Redis 集群的 OPS 就更高了。
问题: 对于异步造成的数据丢失等一致性问题,一般会有定时任务一直在比对,以便最快发现问题,进行修复。
2、读服务降级,故障场景下紧急降级快速止损
Redis 缓存之外,又增加了 ES 缓存。当然了,你可以建立多个缓存副本,比如主 Redis 缓存外,再建立副 Redis 缓存,或者再增加 ES 缓存,这些都可以的,不过相应会增加你的资源成本和代码编写的复杂度。
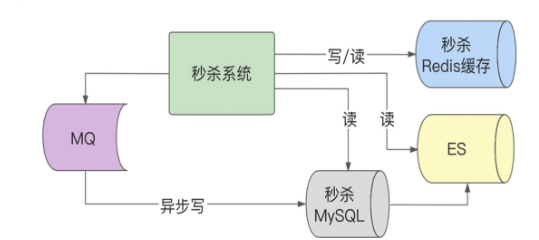
3、简化系统功能,干掉一些不必要的流程,舍弃非核心功能
热点数据
解决单个商品的高并发读和高并发写问题,也就是要处理好热点数据问题。
本地缓存的实现比较简单,可以用 HashMap、Ehcache,或者 Google 提供的 Guava 组件。
写热点:可以通过把一个热 key 拆解成多个 key 的方式,避免热点问题。这种设计涉及到对库存进行再细分,以及子库存挪动,非常复杂,而且边界问题比较多,容易出现少卖或者超卖问题,一般不推荐这种方法。
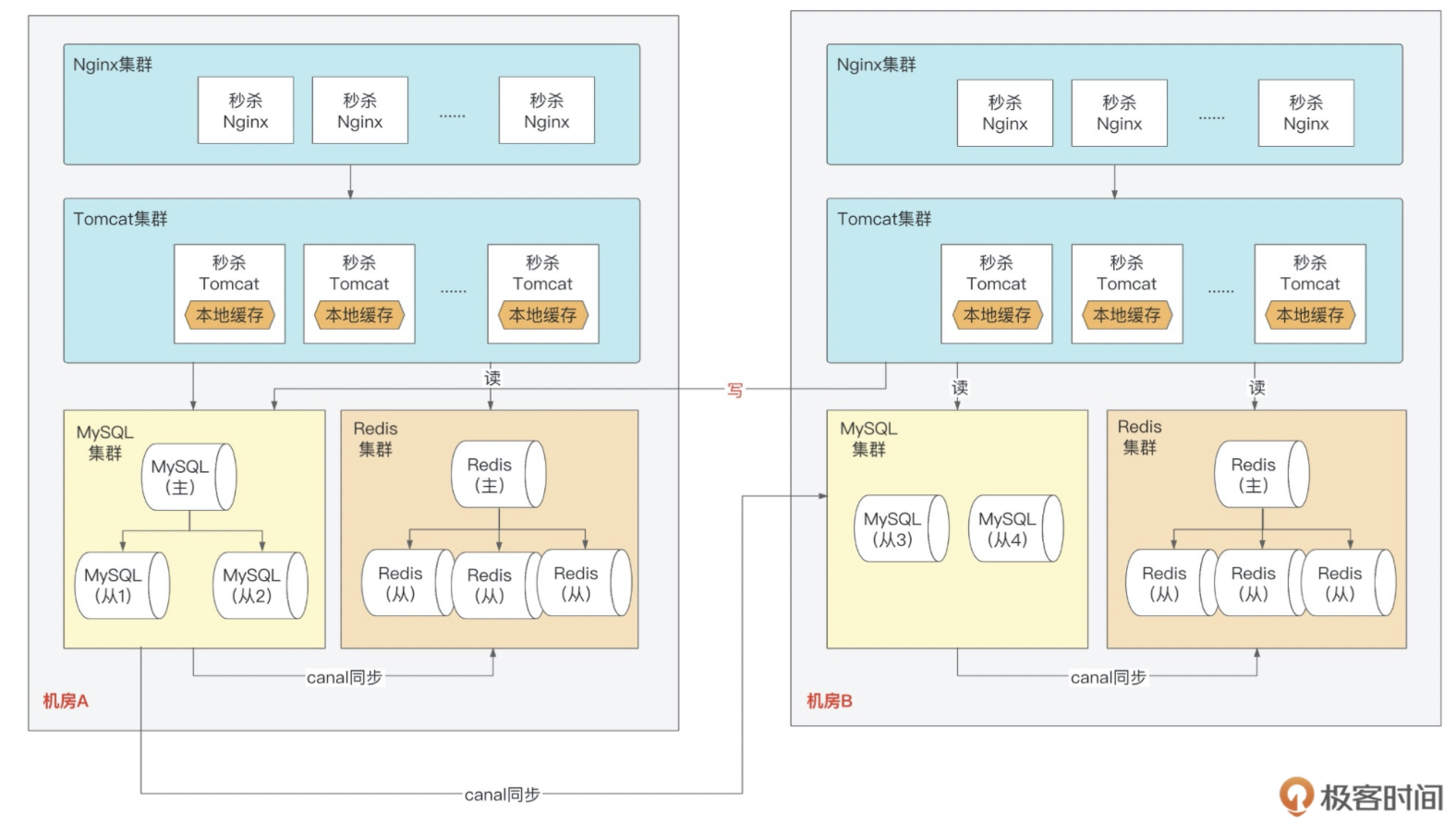
容灾
一般是指搭建多套(两套或以上)相同的系统,当其中一个系统出现故障时,其他系统能快速进行接管,从而持续提供 7*24 不间断业务。
1.3.3.1.4. 防刷和风控
1.3.3.1.4.1. 防刷:Nginx 有条件限流
这种方式可以有效解决黑产流量对单个接口的高频请求
#limit by user
limit_req_zone $user_id zone=limit_by_user:10m rate=1r/s;
#声明一个内存,进程间共享:动态黑名单内存
lua_shared_dict black_hole 50m;
#声明一个内存,进程间共享:活动信息内存
lua_shared_dict activity 5m;
1.3.3.1.4.2. 防刷:Token 机制
这种机制可以有效防止黑产流量跳过中间接口,直接调用下单接口。通过该机制 +Nginx 有条件限流机制,
server {
listen 7081;
#设置真实的域名
#server_name test.com;
#设置header中的host
#proxy_set_header Host test.com;
error_log logs/domain-error.log error;
access_log logs/domain-access.log access;
default_type text/plain;
charset utf-8;
#security token
set $st "";
#产品编号
set $product_id "";
#用户ID
set_by_lua_file $user_id /Users/wangzhangfei5/Documents/seckillproject/demo-nginx/lua/set_common_var.lua;
#活动数据查询
location /activity/query{
limit_req zone=limit_by_user nodelay;
content_by_lua_file /Users/wangzhangfei5/Documents/seckillproject/demo-nginx/lua/activity_query.lua;
#设置返回的header,并将security token放在header中
header_filter_by_lua_block{
ngx.header["st"] = ngx.md5(ngx.var.user_id.."1")
--这里为了解决跨域问题设置的,不存在跨域时不需要设置以下header
ngx.header["Access-Control-Expose-Headers"] = "st"
ngx.header["Access-Control-Allow-Origin"] = "http://localhost:8080"
ngx.header["Access-Control-Allow-Credentials"] = "true"
}
}
#进结算页页面(H5)
location /settlement/prePage{
default_type text/html;
rewrite_by_lua_block{
--校验活动查询的st
local _st = ngx.md5(ngx.var.user_id.."1")
--校验不通过时,以500状态码,返回对应错误页
if _st ~= ngx.var.st then
ngx.log(ngx.ERR,"st is not valid!!")
return ngx.exit(500)
end
--校验通过时,再生成个新的st,用于下个接口校验
local new_st = ngx.md5(ngx.var.user_id.."2")
--ngx.exec执行内部跳转,浏览器URL不会发生变化
--ngx.redirect(url,status) 其中status为301或302
local redirect_url = "/settlement/page".."?productId="..ngx.var.product_id.."&st="..new_st
return ngx.redirect(redirect_url,302)
}
error_page 500 502 503 504 /html_fail.html;
}
#进结算页页面(H5)
location /settlement/page{
default_type text/html;
proxy_pass http://backend;
error_page 500 502 503 504 /html_fail.html;
}
#结算页页面初始化渲染所需数据
location /settlement/initData{
access_by_lua_block{
local _st = ngx.md5(ngx.var.user_id.."2")
if _st ~= ngx.var.st then
return ngx.exit(500)
end
}
proxy_pass http://backend;
header_filter_by_lua_block{
ngx.header["st"] = ngx.md5(ngx.var.user_id.."3")
ngx.header["Access-Control-Expose-Headers"] = "st"
}
error_page 500 502 503 504 @json_fail;
}
#结算页提交订单
location /settlement/submitData{
access_by_lua_file /Users/wangzhangfei5/Documents/seckillproject/demo-nginx/lua/submit_access.lua;
proxy_pass http://backend;
error_page 500 502 503 504 @json_fail;
}
#结算页用户行为操作。模糊匹配
location ~* /useAction/{
proxy_pass http://backend;
}
#静态资源匹配,模糊匹配,如果静态资源上到CDN,这里就可以不用了
location ^~ /images/{
set_by_lua_block $user_id{
}
proxy_pass http://backend;
}
#模拟登录
location /login{
content_by_lua_block{
local user_id = ngx.var.arg_user_id
ngx.header['Set-Cookie'] = 'user_id='..user_id..';path=/; Expires=' .. ngx.cookie_time(ngx.time() + 60 * 60*24)
ngx.say("login success!!!")
}
}
include /Users/wangzhangfei5/Documents/seckillproject/demo-nginx/domain/public.com;
}
1.3.3.1.4.3. 防刷:黑名单机制
-- 黑名单缓存功能
local _CACHE = {}
-- 共享内存区域,用于统计黑名单以及保存黑名单
local hole = ngx.shared.black_hole
-- 请求计数key的前缀
local count_prefix = "co_"
-- 黑名单key的前缀
local black_prefix = "bl_"
-- 过滤请求,如果没有触碰黑名单规则,则返回true,反之则返回false
function _CACHE.filter(key)
-- 参数1 key, 参数2 步长,参数3 如果key不存在时的初始化值 ,参数4 初始化值的失效时间
local after_count = hole:incr(count_prefix..key, 1, 0, 1)
-- 如果为空,则是异常了,这里不做拦截,防止误杀
if not after_count then
return true
end
-- 判断1秒内的请求频率,如果大于设定阈值,则加入黑名单
if after_count > 1 then
ngx.log(ngx.ERR,key.." was caught !!!")
-- 存入本地cache,有效期15秒
local suc, err = hole:set(black_prefix..key,1,15)
if not suc
then
ngx.log(ngx.ERR,key.." set to cache fail : "..err)
end
return false
end
return true
end
-- 校验是否合法,如果在黑名单,则返回false,如果不在,则返回true
function _CACHE.check(key)
local value = hole:get(black_prefix..key)
if not value then
return true
end
return false
end
return _CACHE
1.3.3.1.4.4. 风控
在不同的业务场景下,检查用户画像中的某些数据,是否触碰了红线,或者是某几项综合数据,是否触碰了红线。而有了完善的用户画像,那些黑产用户,在风控的照妖镜下,自然也就无处遁形了。
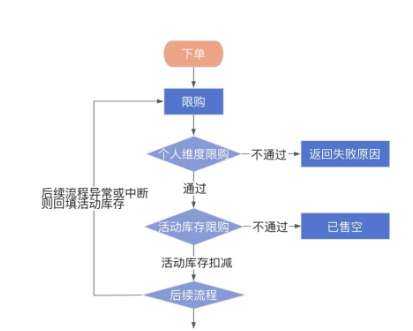
1.3.3.1.5. 秒杀的库存和限购
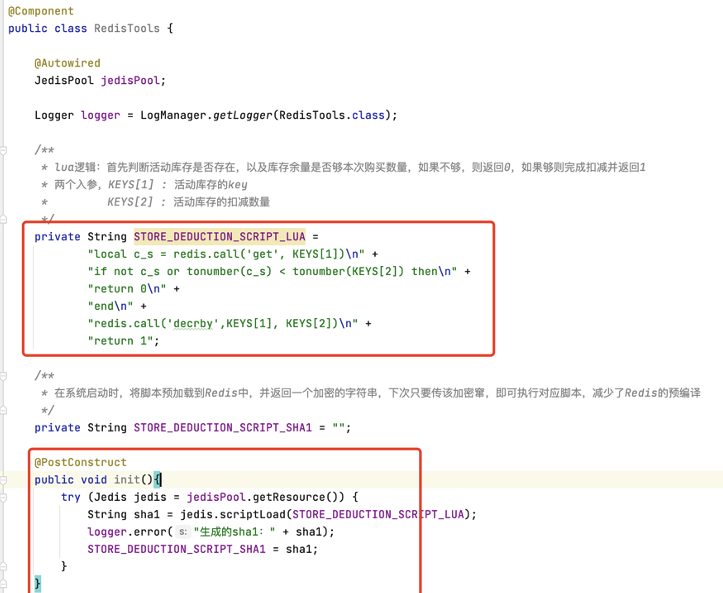
Redis 有个功能,是可以执行 Lua 脚本的(我们 Nginx 服务也有用到 Lua 语言,看来 Lua 语言的适用场景还真不少),并且可以保证脚本中的所有逻辑会在一次执行中按顺序完成。而在 Lua 脚本中,又可以调用 Redis 的原生 API,这样就能同时满足顺序性和原子性的要求了。
Eval :需要每次都传入 Lua 脚本字符串,不仅浪费网络开销,同时 Redis 需要每次重新编译 Lua 脚本,对于我们追求性能极限的系统来说,不是很完美。
另一个命令 EVALSHA:
-- 调用Redis的get指令,查询活动库存,其中KEYS[1]为传入的参数1,即库存key
local c_s = redis.call('get', KEYS[1])
-- 判断活动库存是否充足,其中KEYS[2]为传入的参数2,即当前抢购数量
if not c_s or tonumber(c_s) < tonumber(KEYS[2]) then
return 0
end
-- 如果活动库存充足,则进行扣减操作。其中KEYS[2]为传入的参数2,即当前抢购数量
redis.call('decrby',KEYS[1], KEYS[2])
1.3.3.1.6. 性能调优
1.3.3.1.6.1. CPU 模式的优化
PowerSave、OnDemand、Interactive、Performance
像大促期间或者某段时间部分商品持续大力度营销,这时的活动非常火热,流量也高,所以我们需要将 CPU 模式调整成 Performance,即高性能模式。这时 CPU 一直处于超频状态,当然这种状态也是比较耗电的,但是为了更好地开展活动,还是需要打开的。流量相对稳定的时候我们就可以将 CPU 模式切回成 PowerSave 模式,即节能模式
1.3.3.1.6.2. 网卡中断优化
操作的过程大致可以分成 3 步:查看在流量高峰时,是否处理网卡中断的工作都集中在同一个核上;找到网卡中断的 IRQ(硬件设备的一个编号,让 CPU 知道是哪个硬件的中断信号);将网卡的 IRQ 与一个特定的 CPU 核进行绑定。我们这么做的目的,其实就是在多核 CPU 下,让一个进程在某个给定的 CPU 上尽量长时间地运行而不被迁移到其他处理器。这样做的好处就是:一方面可以减少 CPU 调度产生的开销;另一方面可以提高每个 CPU 核的缓存命中率。
1.3.3.1.6.3. Nginx 配置优化
全局模块配置worker_processes: 工作进程数和 CPU 核数保持一致,这是种比较理想的状态
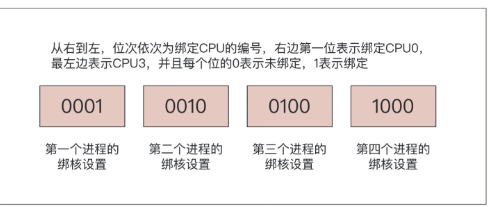
worker_cpu_affinity :绑核的目的,上面也已经介绍过了。当我们了解了机器的配置,以及部署在机器的应用以后,我们就可以合理地分配 CPU 资源,以 4 核 CPU 绑核为例,其绑定语法如下:
worker_cpu_affinity 0001 0010 0100 1000;
events 模块配置: worker_connections、worker_rlimit_nofile 将这两个的配置值都设置为 65535
accept_mutex:流量较小时,建议打开,相反,则建议关闭
accept_mutex_delay:该指令是配合 accept_mutex 来使用,是设置工作进程取得互斥锁后接受新连接的超时时间
HTTP 模块配置:
sendfile:这个是操作系统用来优化文件传输提供的一个函数。
#工作进程:根据CPU核数以及机器实际部署项目来定,建议小于等于实际可使用CPU核数
worker_processes 2;
#绑核:MacOS不支持。
#worker_cpu_affinity 01 10;
#工作进程可打开的最大文件描述符数量,建议65535
worker_rlimit_nofile 65535;
#日志:路径与打印级别
error_log logs/error.log error;
events {
#指定处理连接的方法,可以不设置,默认会根据平台选最高效的方法,比如Linux是epoll
#use epoll;
#一个工作进程的最大连接数:默认512,建议小于等于worker_rlimit_nofile
worker_connections 65535;
#工作进程接受请求互斥,默认值off,如果流量较低,可以设置为on
#accept_mutex off;
#accept_mutex_delay 50ms;
}
http {
#关闭非延时设置
tcp_nodelay off;
#优化文件传输效率
sendfile on;
#降低网络堵塞
tcp_nopush on;
#与客户端使用短连接
keepalive_timeout 0;
#与下游服务使用长连接,指定HTTP协议版本,并清除header中的Connection,默认是close
proxy_http_version 1.1;
proxy_set_header Connection "";
#将客户端IP放在header里传给下游,不然下游获取不到客户端真实IP
proxy_set_header X-Real-IP $remote_addr;
#与下游服务的连接建立超时时间
proxy_connect_timeout 500ms;
#向下游服务发送数据超时时间
proxy_send_timeout 500ms;
#从下游服务拿到响应结果的超时时间(可以简单理解成Nginx多长时间内,拿不到响应结果,就算超时),
#这个根据每个接口的响应性能不同,可以在每个location单独设置
proxy_read_timeout 3000ms;
#开启响应结果的压缩
gzip on;
#压缩的最小长度,小于该配置的不压缩
gzip_min_length 1k;
#执行压缩的缓存区数量以及大小,可以使用默认配置,根据平台自动变化
#gzip_buffers 4 8k;
#执行压缩的HTTP请求的最低协议版本,可以不设置,默认就是1.1
#gzip_http_version 1.1;
#哪些响应类型,会执行压缩,如果静态资源放到CDN了,那这里只要配置文本和html即可
gzip_types text/plain;
#acccess_log的日志格式
log_format access '$remote_addr - $remote_user [$time_local] "$request" $status '
'"$upstream_addr" "$upstream_status" "$upstream_response_time" userId:"$user_id"';
#加载lua文件
lua_package_path "/Users/~/Documents/seckillproject/demo-nginx/lua/?.lua;;";
#导入其他文件
include /Users/~/Documents/seckillproject/demo-nginx/domain/domain.com;
include /Users/~/Documents/seckillproject/demo-nginx/domain/internal.com;
include /Users/~/Documents/seckillproject/demo-nginx/config/upstream.conf;
include /Users/~/Documents/seckillproject/demo-nginx/config/common.conf;
}
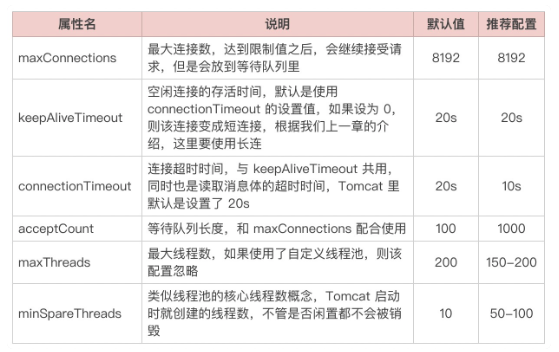
1.3.3.1.6.4. tomcat
1.3.3.1.7. Vertx
内部提供的几乎所有接口都支持异步,并且所有的操作都是基于事件来实现程序的非阻塞运行。再加上它的网络通信框架集成了 Netty,其内部的零拷贝机制、基于内存池的缓冲区重用机制,还有高性能的序列化框架,以及它本身的 Multi-Reactor 模式,总结来看它的性能是要优于 Tomcat 的