1.5.2.1.1. Redis 数据结构
1.5.2.1.1.1. string
最多存储512M
set <key><value>
*NX:当数据库中key不存在时,可以将key-value添加数据库
*XX:当数据库中key存在时,可以将key-value添加数据库,与NX参数互斥
*EX:key的超时秒数
*PX:key的超时毫秒数,与EX互斥
1.5.2.1.1.2. list
底层是双向链表对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差
数据少时是zipList(压缩列表).多的时候会用quickList,分配是连续内存
Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用
lpush/rpush <key><value1><value2><value3> .... 从左边/右边插入一个或多个值。
lpop/rpop <key>从左边/右边吐出一个值。值在键在,值光键亡。
rpoplpush <key1><key2>从<key1>列表右边吐出一个值,插到<key2>列表左边。
lrange <key><start><stop>
按照索引下标获得元素(从左到右)
lrange mylist 0 -1 0左边第一个,-1右边第一个,(0-1表示获取所有)
lindex <key><index>按照索引下标获得元素(从左到右)
llen <key>获得列表长度
linsert <key> before <value><newvalue>在<value>的后面插入<newvalue>插入值
lrem <key><n><value>从左边删除n个value(从左到右)
lset<key><index><value>将列表key下标为index的值替换成value
1.5.2.1.1.3. SET
set是可以自动排重 ,Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的\复杂度都是O(1)**
sadd <key><value1><value2> .....
将一个或多个 member 元素加入到集合 key 中,已经存在的 member 元素将被忽略
smembers <key>取出该集合的所有值。
sismember <key><value>判断集合<key>是否为含有该<value>值,有1,没有0
scard<key>返回该集合的元素个数。
srem <key><value1><value2> .... 删除集合中的某个元素。
spop <key>随机从该集合中吐出一个值。
srandmember <key><n>随机从该集合中取出n个值。不会从集合中删除 。
smove <source><destination>value把集合中一个值从一个集合移动到另一个集合
sinter <key1><key2>返回两个集合的交集元素。
sunion <key1><key2>返回两个集合的并集元素。
sdiff <key1><key2>返回两个集合的差集元素(key1中的,不包含key2中的)
1.5.2.1.1.4. HASH
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。
hset <key><field><value>给<key>集合中的 <field>键赋值<value>
hget <key1><field>从<key1>集合<field>取出 value
hmset <key1><field1><value1><field2><value2>... 批量设置hash的值
hexists<key1><field>查看哈希表 key 中,给定域 field 是否存在。
hkeys <key>列出该hash集合的所有field
hvals <key>列出该hash集合的所有value
hincrby <key><field><increment>为哈希表 key 中的域 field 的值加上增量 1 -1
hsetnx <key><field><value>将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在 .
1.5.2.1.1.5. ZSET
有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合
不同之处是有序集合的每个成员都关联了一个\评分(score)**,这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map
zset底层使用了两个数据结构
(1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
(2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。按层级搜索
1.5.2.1.1.6. bitMap
Redis提供了Bitmaps这个“数据类型”可以实现对位的操作:
(1) Bitmaps本身不是一种数据类型, 实际上它就是字符串(key-value) , 但是它可以对字符串的位进行操作。
(2) Bitmaps单独提供了一套命令, 所以在Redis中使用Bitmaps和使用字符串的方法不太相同。 可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量。
1.5.2.1.1.7. HyperLogLog
HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
1.5.2.1.1.8. Geospatial
GEO,Geographic,地理信息的缩写。该类型,就是元素的2维坐标,在地图上就是经纬度。redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作
1.5.2.1.2. 持久化
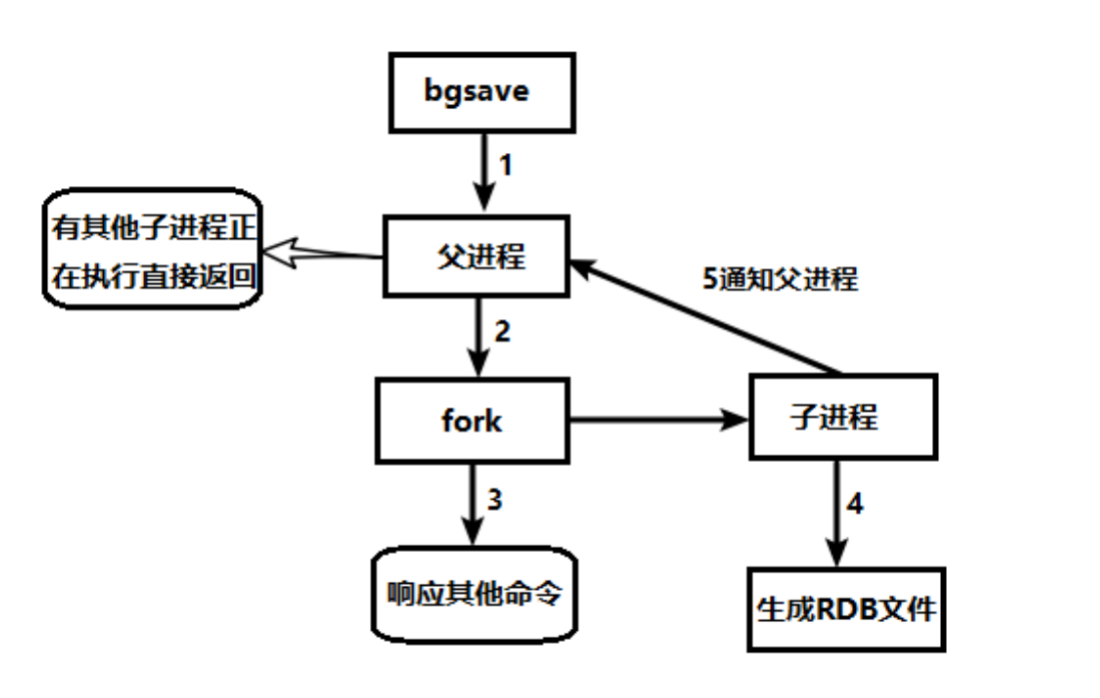
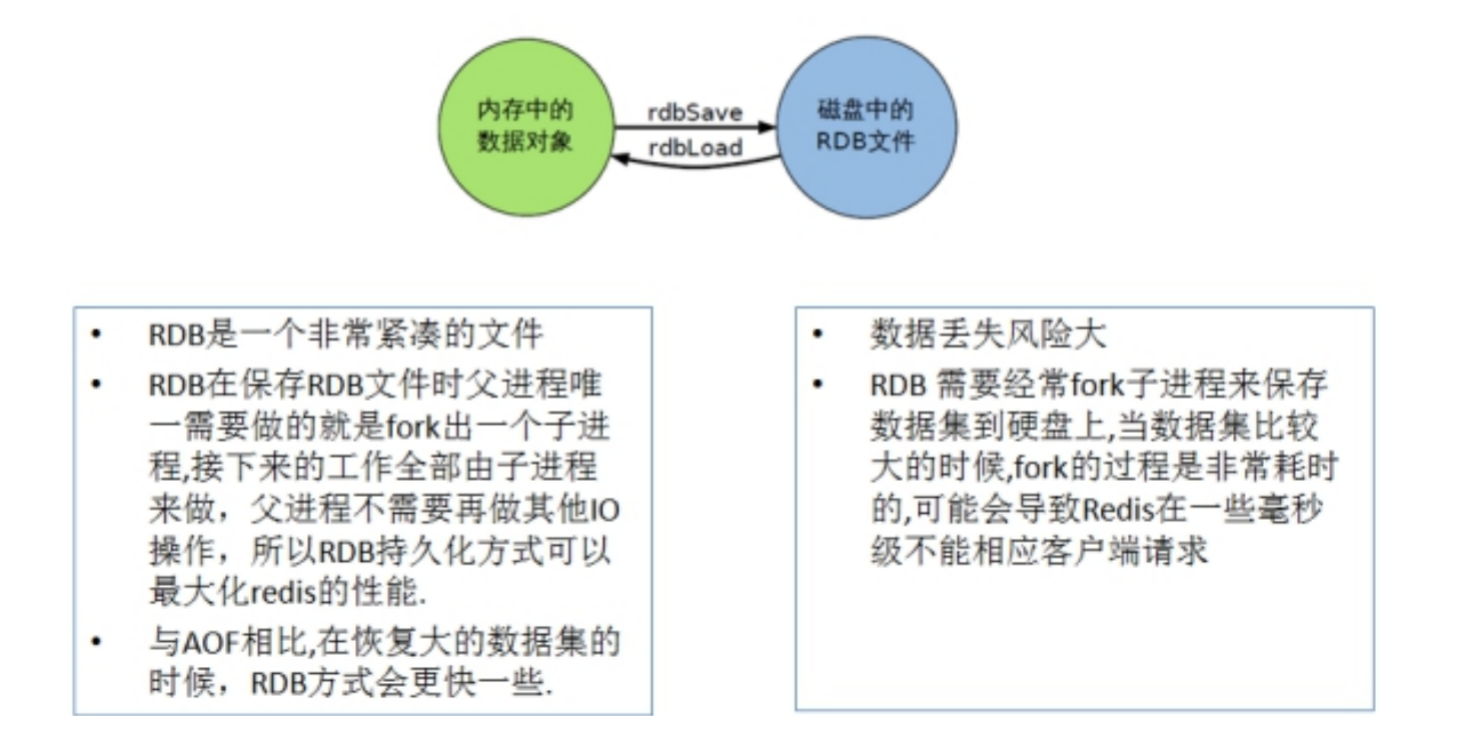
1.5.2.1.2.1. RDB(Redis DataBase)
RDB的缺点是最后一次持久化后的数据可能丢失
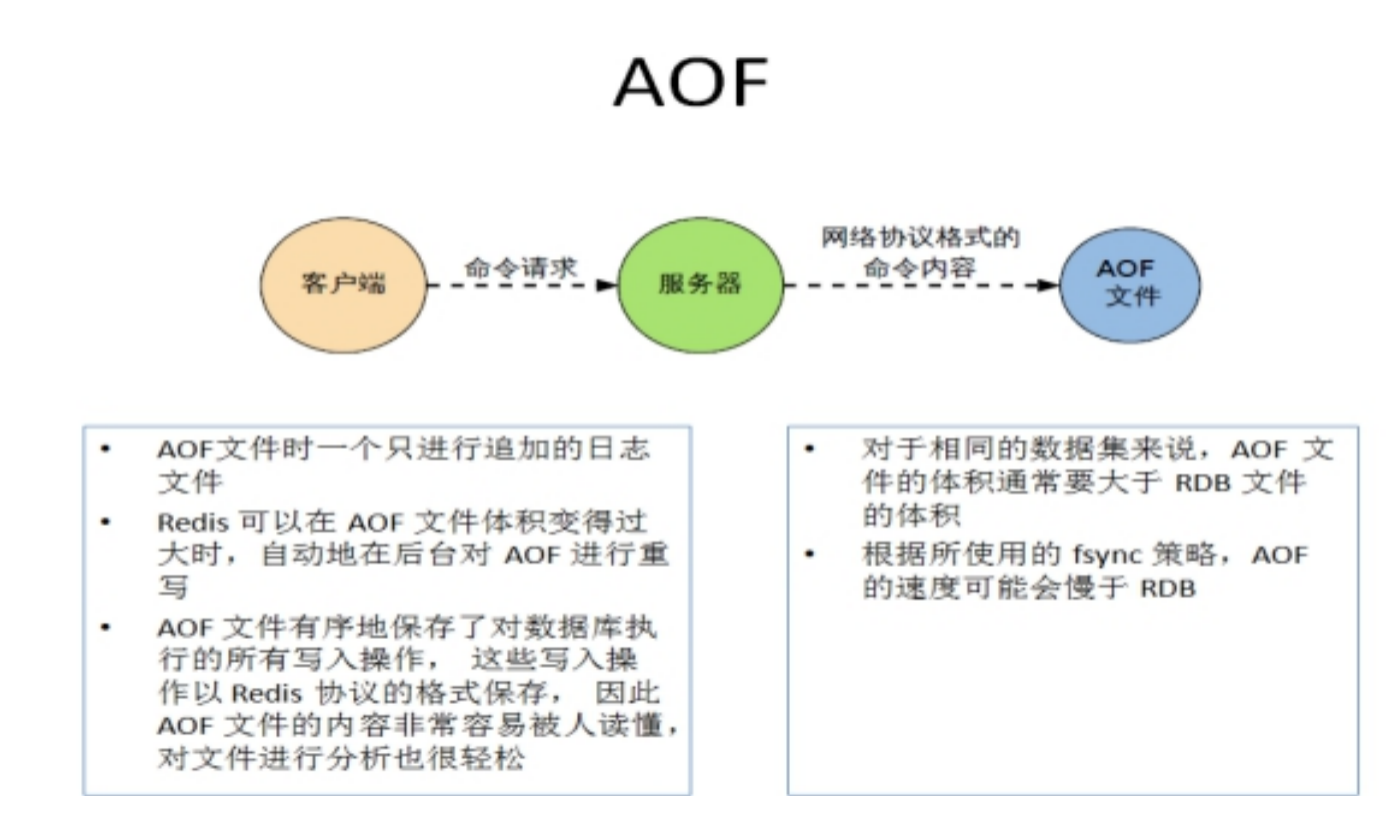
1.5.2.1.2.2. AOF(Append Of File)
以日志形式来记录每个写操作(增量保存)
AOF和RDB同时开启,系统默认取AOF的数据(数据不会存在丢失)
- appendfsync always
始终同步,每次Redis的写入都会立刻记入日志;性能较差但数据完整性比较好
- appendfsync everysec
每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失。
- appendfsync no
redis不主动进行同步,把同步时机交给操作系统。
RDB文件只用作后备用途,建议只在Slave上持久化RDB文件,而且只要15分钟备份一次就够了,只保留save 900 1这条规则
如果使用AOF,好处是在最恶劣情况下也只会丢失不超过两秒数据,启动脚本较简单只load自己的AOF文件就可以了。
代价,一是带来了持续的IO,二是AOF rewrite的最后将rewrite过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的。
只要硬盘许可,应该尽量减少AOF rewrite的频率,AOF重写的基础大小默认值64M太小了,可以设到5G以上。
1.5.2.1.3. 缓存传透
对空值判断
设置可访问白名单
使用bitmaps类型定义一个可以访问的名单,名单id作为bitmaps的偏移量,每次访问和bitmap里面的id进行比较,如果访问id不在bitmaps里面,进行拦截,不允许访问。
采用布隆过滤器
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。)
将所有可能存在的数据哈希到一个足够大的bitmaps中,一个一定不存在的数据会被 这个bitmaps拦截掉,从而避免了对底层存储系统的查询压力。
- 进行实时监控
当发现Redis的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务
1.5.2.1.4. 缓存雪崩
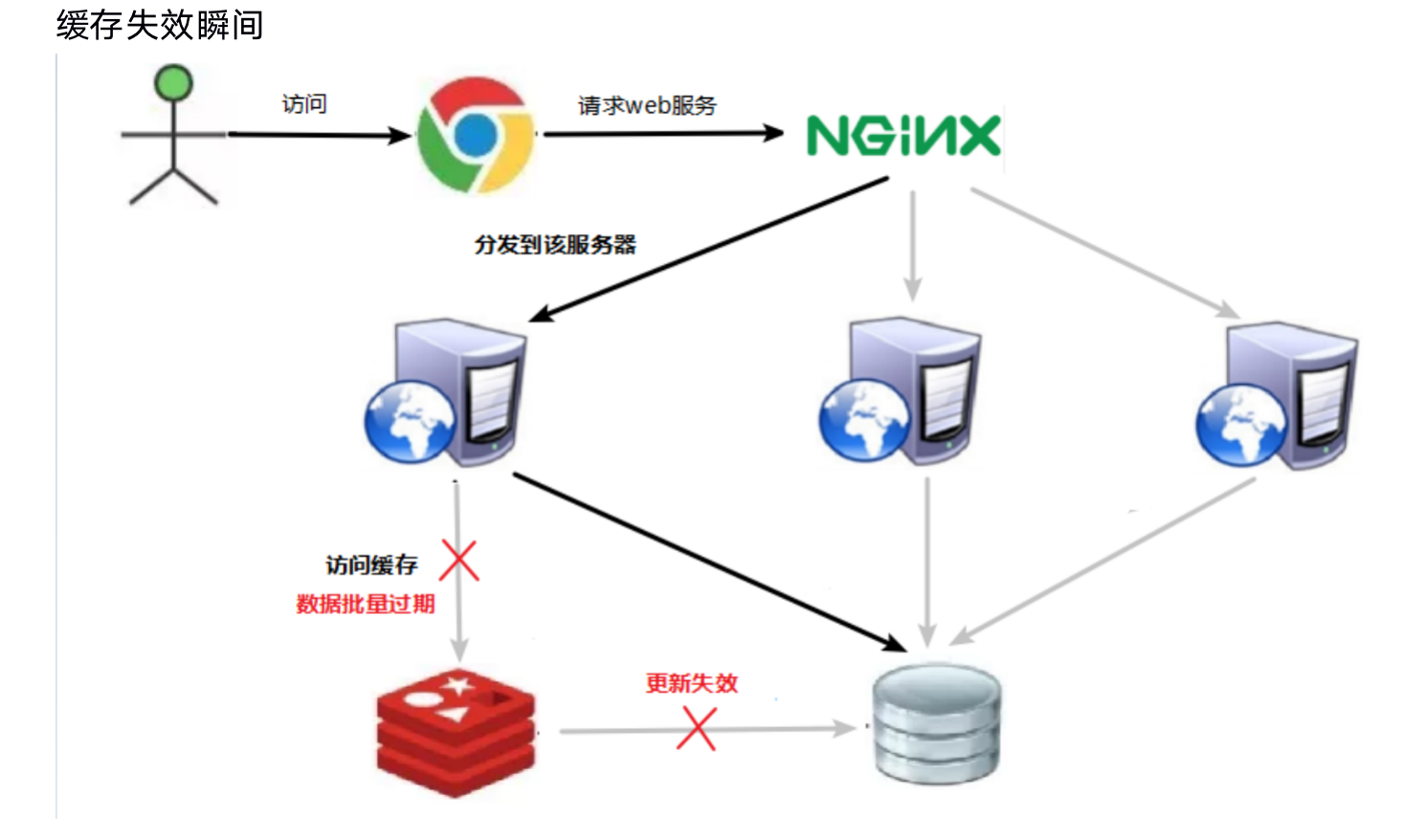
多级缓存 (nginx缓存 + redis缓存 +其他缓存(ehcache等)
设置过期标志更新缓存
记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
将缓存失效时间分散
1.5.2.1.5. 分布式锁
基于数据库实现分布式锁
基于缓存(Redis等)
性能高基于Zookeeper
可靠性
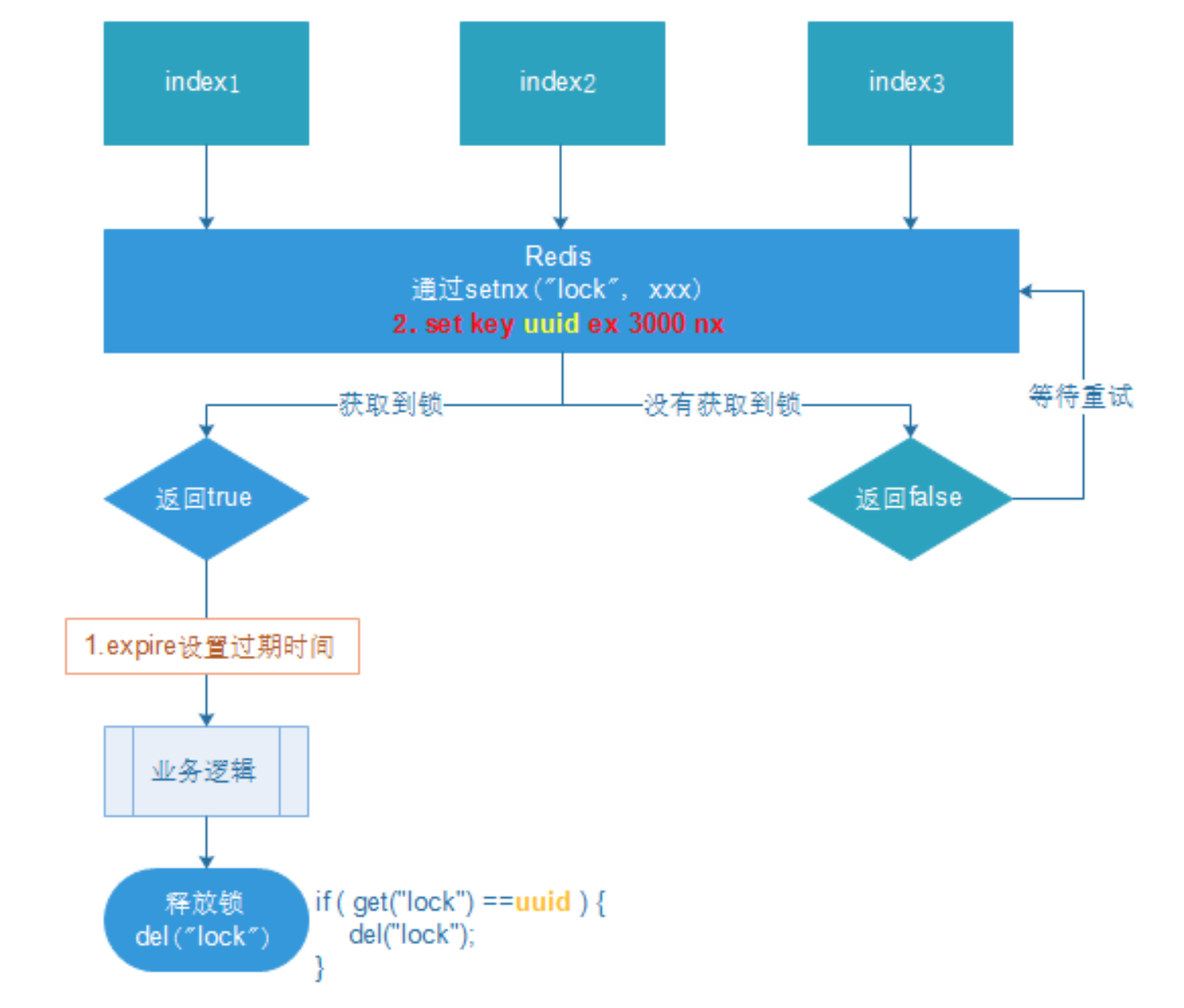
实现逻辑总结:
- 加载,使用uuid存储,用于判断比较误删,设置过期时间
- 使用lua释放锁
- 重试
@GetMapping("testLockLua")
public void testLockLua() {
//1 声明一个uuid ,将做为一个value 放入我们的key所对应的值中
String uuid = UUID.randomUUID().toString();
//2 定义一个锁:lua 脚本可以使用同一把锁,来实现删除!
String skuId = "25"; // 访问skuId 为25号的商品 100008348542
String locKey = "lock:" + skuId; // 锁住的是每个商品的数据
// 3 获取锁
Boolean lock = redisTemplate.opsForValue().setIfAbsent(locKey, uuid, 3, TimeUnit.SECONDS);
// 第一种: lock 与过期时间中间不写任何的代码。
// redisTemplate.expire("lock",10, TimeUnit.SECONDS);//设置过期时间
// 如果true
if (lock) {
// 执行的业务逻辑开始
// 获取缓存中的num 数据
Object value = redisTemplate.opsForValue().get("num");
// 如果是空直接返回
if (StringUtils.isEmpty(value)) {
return;
}
// 不是空 如果说在这出现了异常! 那么delete 就删除失败! 也就是说锁永远存在!
int num = Integer.parseInt(value + "");
// 使num 每次+1 放入缓存
redisTemplate.opsForValue().set("num", String.valueOf(++num));
/*使用lua脚本来锁*/
// 定义lua 脚本
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 使用redis执行lua执行
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
// 设置一下返回值类型 为Long
// 因为删除判断的时候,返回的0,给其封装为数据类型。如果不封装那么默认返回String 类型,
// 那么返回字符串与0 会有发生错误。
redisScript.setResultType(Long.class);
// 第一个要是script 脚本 ,第二个需要判断的key,第三个就是key所对应的值。
redisTemplate.execute(redisScript, Arrays.asList(locKey), uuid);
} else {
// 其他线程等待
try {
// 睡眠
Thread.sleep(1000);
// 睡醒了之后,调用方法。
testLockLua();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
哨兵
sentinel集群通过raft算法保证分布式一致性。基于投票算法,只要保证过半数节点通过提议即可。
1.5.2.1.6. 6.0新特性
支持IO多线程,网络io交互处理模块多线程,而非执行命令多线程
工具支持 Cluster(集群)
RESP3新的 Redis 通信协议